


#40 |A relação entre a Nestlé e o desmatamento e a ofensiva antitrans no Legislativo brasileiro
Uma newsletter sobre jornalismo investigativo baseada em dados do projeto CruzaGrafos e em investigações brasileiras

Olá!
Eu sou Flávia Faria* e esta é mais uma edição da Investigadora. Hoje vamos falar sobre a colaboração entre O Joio e o Trigo e o Bureau of Investigative Journalism que resultou numa investigação sobre a cadeia de produção de colágeno vendido pela Nestlé e seu elo com desmatamento e pressão sobre terras e povos indígenas na Amazônia.
Trazemos também os bastidores da reportagem de Dani Avelar para a Folha de S.Paulo com um levantamento de projetos de lei que visam restringir direitos da população trans nas diferentes instâncias do Legislativo brasileiro.
Na dica do dia você vai aprender como utilizar o ChatGPT no Google Docs para facilitar tarefas na hora de editar e escrever textos.
Se esta é a sua primeira vez por aqui, sinta-se em casa. Esta é uma newsletter sobre jornalismo investigativo baseada em dados do projeto CruzaGrafos – parceria da Abraji (Associação Brasileira de Jornalismo Investigativo) e do Brasil.IO, com o apoio da Google News Initiative.
O CruzaGrafos está disponível para todos os associados da Abraji. Para não associados, basta clicar aqui. Quem quiser fazer parte da Abraji pode ver os passos para se associar neste link. E aqui dá para apoiar o Brasil.IO.
Também temos agora um canal privado no Telegram para divulgar as novidades do CruzaGrafos — há poucos dias, por exemplo, atualizamos as informações da Receita e do Ibama.
Boa leitura!
Quando a notícia tem cheiro
No dia a dia das redações, não é incomum que grandes pautas surjam de desdobramentos de outras apurações. É o caso da investigação que ligou o colágeno comprado pela Nestlé ao desmatamento e exploração de indígenas no Brasil.
A reportagem de Fábio Zuker, de O Joio e O Trigo, e de Elisângela Mendonça e Andrew Wasley, do Bureau of Investigative Journalism, identificou, na cadeia de produção do colágeno, gado criado ilegalmente em áreas desmatadas e invadidas (clique aqui para ler a versão em português e aqui para ler a versão em inglês).
A mercadoria, vendida pela marca suíça como suplemento alimentar, é muitas vezes vista como um subproduto da pecuária, mas pode responder por até 25% do faturamento dos frigoríficos.
A pauta surgiu em meio a outra apuração, que mostrou que um fornecedor da Nestlé usou carne de gado criado de forma ilegal na terra do povo Mỹky, no norte de Mato Grosso.
Elisângela Mendonça conta que dados coorporativos obtidos pela equipe sobre exportação de cargas ligadas à Nestlé indicavam uma anomalia. “Tinha colágeno para caramba saindo do Brasil para a Nestlé, e ninguém nunca prestou atenção nisso antes. Há 7, 8 meses, quando comecei a trabalhar na pauta, não fazia ideia do que era colágeno. Mergulhei para entender de onde isso vinha”, diz.
Um ponto crucial da apuração foi notar que o produto não está coberto pela legislação europeia que visa coibir a entrada de mercadorias ligadas ao desmatamento. É, portanto, uma commodity sem escrutínio e não há obrigação das empresas de reportar sua origem.
Havia, porém, grande dificuldade em linkar toda a cadeia produtora do colágeno, que é extensa e envolve criação de gado, frigoríficos, curtumes e fábricas, especialmente porque as empresas não divulgam os fornecedores de forma detalhada.
“A gente reuniu habilidades técnicas, análise de dados, imagens de satélite, investigou registros das empresas, todo o tipo de material corporativo… E ainda assim não conseguia encontrar conexões. O ‘x’ da questão foi a reportagem de campo”, diz Elisângela.
Aqui, entrou o faro do repórter e antropólogo Fábio Zucker. Ele conta que os caminhões que levavam as raspas e aparas de couro, de onde é extraído o colágeno, tinham um cheiro muito forte, inconfundível.
O cheiro permitiu identificar a carga que provavelmente teria como destino a fábrica de colágeno. Conversando com os caminhoneiros, foi possível entender de onde vinha a carga e para onde ela se destinava —conectando, assim, a cadeia produtora.
Descobriram, por exemplo, que são usados animais de fornecedores indiretos de abatedouros da JBS, da Minerva e da Marfrig.
Depois de entender onde era criado o gado que daria origem ao colágeno vendido pela Nestlé, foi possível, com a colaboração do Center for Climate Crime Analysis (CCCA), encontrar ao menos 2.600 km² de desmatamento conectados à cadeia produtora investigada. A análise foi feita a partir de dados de satélite e utilizou fontes como Prodes e Deter. Na edição #30 já falamos sobre o uso do Prodes em investigações jornalísticas.
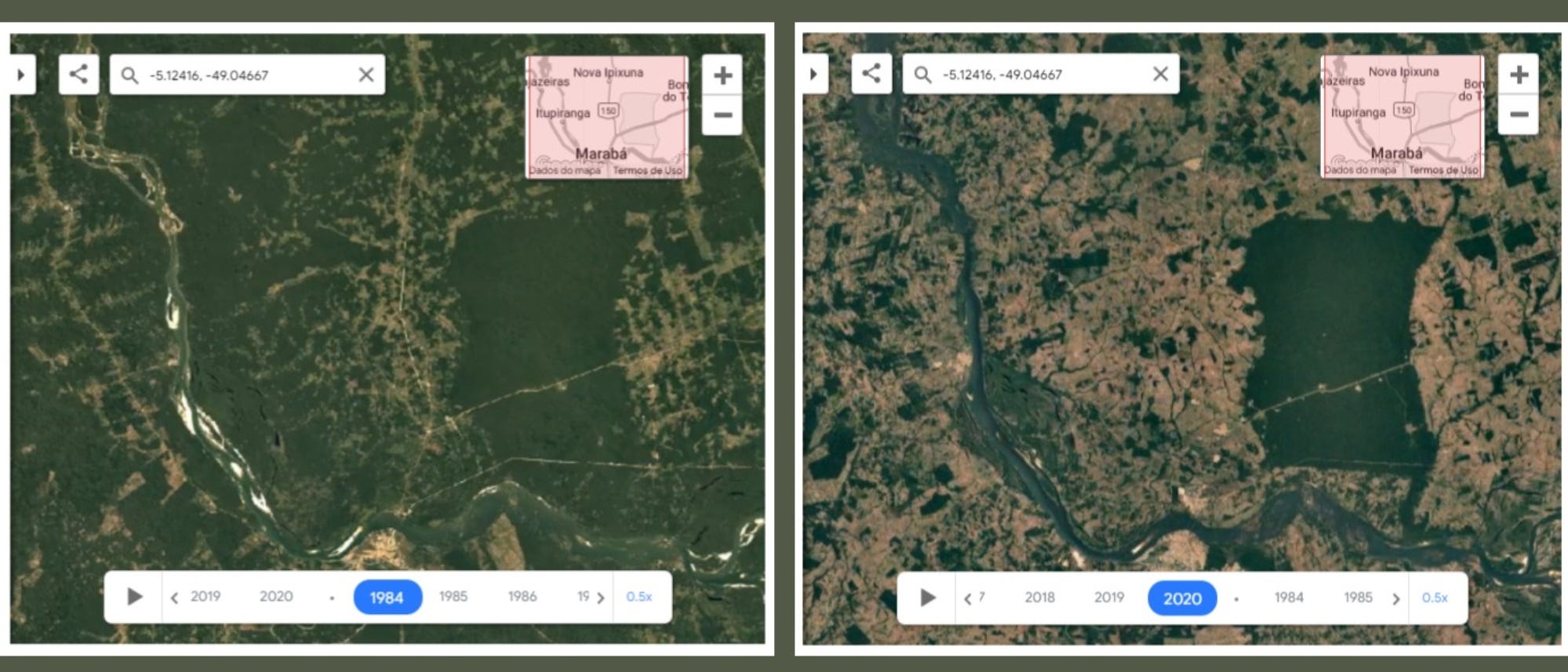
#ParaTodosVerem: Imagem de satélite mostra área da Terra Indígena Mãe-Maria, localizada no município de Bom Jesus do Tocantins, no sudeste do Pará, em 1984, pouco desmatada, e em 2020, com grande área devastada
“Nós somos três jornalistas que tiramos 8 meses das nossas vidas para investigar a cadeia produtora de colágeno. A gente não tem acesso nem a 1% das informações que essas empresas têm. Tudo que tivemos veio com muita dificuldade. Se a gente conseguiu, com uma fração ínfima de informação, mapear essa cadeia e mostrar irregularidades, o que essas empresas, que têm acesso ao banco de dados de todos os fornecedores, não poderiam estar fazendo?”, questiona Fábio.
Direitos trans sob ameaça
Foi uma ofensiva de discursos de vereadores e deputados conservadores, logo após o Dia Nacional da Visibilidade Trans, em 29 de janeiro, que acendeu o alerta para a repórter da Folha Dani Avelar.
A isso se somou o crescente movimento entre legisladores dos Estados Unidos para lançar projetos de lei que restringem direitos da população trans, e a expectativa de que a direita brasileira pudesse se apropriar dessa estratégia.
No último dia 20, foi ao ar a reportagem que mostrou que o Brasil tem um novo projeto de lei antitrans por dia, fruto de levantamento feito por Dani no Congresso Nacional, nas Assembleias Legislativas e nas Câmaras Municipais das capitais e de algumas cidades consideradas estratégicas (onde há atendimento para pessoas trans no SUS, por exemplo).
O primeiro passo foi pensar como seria elaborado o levantamento e desenvolver uma metodologia. Para isso, Dani conversou com pesquisadores que tinham feito estudos similares, no Brasil e nos EUA, em universidades e em organizações que atuam na defesa dos direitos das pessoas trans (veja aqui, aqui e aqui alguns exemplos de trabalhos que inspiraram a pesquisa).
Uma grande dificuldade é o fato de que o Brasil não tem um local que concentre projetos de lei nas diferentes instâncias legislativas e que facilite automatizar ou sintetizar a busca. Nos EUA, por exemplo, há o Legiscan, com leis estaduais e federais.

#ParaTodosVerem: print do site Legiscan, que reúne projetos de lei federais e estaduais nos Estados Unidos
A Câmara e o Senado brasileiros disponibilizam API que permite acessar mais facilmente os projetos, mas não há algo do tipo no Legislativo estadual ou municipal.
Como não havia modo de automatizar todo o processo de maneira rápida, Dani optou por fazer a pesquisa individual e manualmente no portal de cada Casa —e não raro elas têm sistemas de busca muito diferentes entre si.
A repórter conta que, inicialmente, a ideia era levantar os projetos que tratassem da saúde de pessoas trans e do acesso na rede pública a terapias voltadas a essa população.
A pesquisa prática, contudo, mostrou que a ofensiva conservadora se espalhava por outras áreas, como educação e esporte. Aí foi preciso ampliar a lista de palavras-chaves que guiavam a busca.
“Comecei pesquisando por ‘gênero’, ‘transição de gênero’, ‘bloqueio puberal’ e ‘hormonioterapia’. Eram palavras-chave que apareciam no projeto de lei de Mario Frias [(PL-SP) sobre o acesso a tratamentos na rede pública]. Depois incluí termos como ‘banheiro unissex’ ou ‘multigênero’, ‘linguagem neutra’, ‘ideologia de gênero’, ‘escola sem partido’ e ‘sexo biologico’ —essa última era importante pra encontrar projetos sobre esporte”, relata Dani.
O resultado foram 69 projetos de lei (você pode conferir todos eles aqui). Do início do levantamento à publicação da reportagem foram quase dois meses de trabalho.
“Infelizmente, fazer acompanhamento legislativo é um trabalho meio ingrato, muito braçal, muito repetitivo. É preciso atentar aos critérios de busca, às palavras-chaves, e ao longo da minha pesquisa tive que recomeçar com critérios mais amplos. É importante não se prender às palavras-chave iniciais”, complementa.
ChatGPT chega ao Google Docs
Há algum tempo a internet parece só falar em ChatGPT e outras inteligências artificiais generativas. Pois o robô que promete facilitar a vida (ou não) agora pode ser integrado ao Google Docs.
Para usar a ferramenta no editor de textos do Google é preciso seguir alguns passos, como instalar uma extensão no Chrome e gerar uma chave de API. Você confere aqui as instruções completas (em inglês), mas o processo é bem simples.
Dentro do Docs, o ChatGPT pode ser útil em tarefas do dia a dia. Alguns exemplos:
É possível cortar um texto solicitando à ferramenta que resuma um trecho específico
O texto está repetitivo? Peça que o ChatGPT sugira sinônimos
Peça sugestões de título, com opções de SEO
Solicite a tradução de trechos em outras línguas (algo que pode ser valioso em entrevistas, por exemplo)

#ParaTodosVerem: print mostra extensão do ChatGPT no Google Docs, com barra auxiliar na lateral do documento de texto
Como a própria ferramenta faz questão de lembrar, as respostas do ChatGPT são “geradas com base em modelos estatísticos e podem não ser precisas ou relevantes em todos os casos. Use o bom-senso ao avaliar as respostas e sempre revise e edite o conteúdo gerado antes de usá-lo em seus documentos.”
Além disso, a ferramenta não tem, em português, o mesmo desempenho que apresenta na língua inglesa, então vale redobrar a atenção.
A extensão no Docs é gratuita, mas a OpenAI cobra uma taxa para o uso da API. É possível avaliar o custo-benefício em uma versão de teste, por tempo limitado. Há também uma extensão para o Google Sheets.
Fortaleça o trabalho de quem faz a Investigadora. Contribua com qualquer quantia. O pagamento pode ser feito via Pix, por meio da chave aleatória 61699d2c-28f7-4d90-b618-333a04f13e0a. É só copiar e colá-la. Também dá para usar o QR Code a seguir:

*Flávia Faria é jornalista especializada na cobertura guiada por dados. Foi repórter da Folha e editora do DeltaFolha, núcleo de jornalismo de dados do jornal. Foi finalista do Sigma Awards 2022
Ficou com alguma dúvida? Quer saber sobre os bastidores de uma determinada reportagem ou aprender mais sobre alguma ferramenta? Vem com a gente: cruzagrafos@abraji.org.br.
Para ler as edições passadas da Investigadora, clique aqui.
Saiba mais sobre o CruzaGrafos
Consultamos milhões de dados da Receita Federal do Brasil, do Tribunal Superior Eleitoral e de autos de infração lavrados pelo Ibama.
Temos, por exemplo, candidaturas em eleições, informações sobre empresas e cruzamentos com o Portal da Transparência. Você pode ler mais sobre nossa última atualização do projeto aqui.
O CruzaGrafos, indicado como finalista do Sigma Awards 2021, conta com um programa de treinamentos voltado para redações, grupos de freelancers, universidades e organizações do terceiro setor ligadas à educação e à transparência de dados.
Você pode ler mais sobre o projeto aqui. Preparamos um guia escrito, um vídeo tutorial com legendas em português, inglês e espanhol, além de uma web stories.
Vale lembrar que as informações disponibilizadas pelo CruzaGrafos são públicas, mas o trabalho de curadoria, seleção, limpeza, cruzamento, estudo de relações de poder, diferentes tipos de download (manual, pedidos de LAI, webscraping, OSINT), descrição e pesquisa de exemplos é feito pela equipe da Abraji e do Brasil.IO. Dar crédito às organizações é importante para a manutenção desse trabalho e para mostrar a outros colegas que a ferramenta é útil.
Se você usar a ferramenta como referência para sua reportagem, não se esqueça de citar!
Confira as informações mais recentes do projeto aqui.
O que você achou desta edição da Investigadora?
>> Divulgue a Investigadora: encaminhe a newsletter para seus amigos e compartilhe os conteúdos nas suas redes sociais.